Apache Flume
Generally, most of the data that is to be analyzed will be produced by various data sources like applications servers, social networking sites, cloud servers, and enterprise servers. This data will be in the form of log files and events.
Hadoop File System Shell provides commands to insert data into Hadoop and read from it. You can insert data into Hadoop using the put command as shown below.
$ Hadoop fs –put /path of the required file /path in HDFS where to save the file
Problem with put Command
Using put command, we can transfer only one file at a time while the data generators generate data at a much higher rate. Since the analysis made on older data is less accurate, we need to have a solution to transfer data in real time.
Available Solutions
- Facebook’s Scribe
- Apache Kafka
- Apache Flume
What is Flume?

Apache Flume is a tool/service/data ingestion mechanism for collecting aggregating and transporting large amounts of streaming data such as log files, events (etc...) from various sources to a centralized data store.
Flume is a highly reliable, distributed, and configurable tool. It is principally designed to copy streaming data (log data) from various web servers to HDFS.

Let's see some common sources of Flume

Advantages of Flume
- Using Apache Flume we can store the data in to any of the centralized stores (HBase, HDFS).
- Flume provides the feature of contextual routing.
- The transactions in Flume are channel-based where two transactions (one sender and one receiver) are maintained for each message. It guarantees reliable message delivery.
Apache Flume Use Cases
Architecture
The following illustration depicts the basic architecture of Flume. As shown in the illustration, data generators (such as Facebook, Twitter) generate data which gets collected by individual Flume agents running on them. Thereafter, a data collector (which is also an agent) collects the data from the agents which is aggregated and pushed into a centralized store such as HDFS or HBase.

Components of Flume Architecture
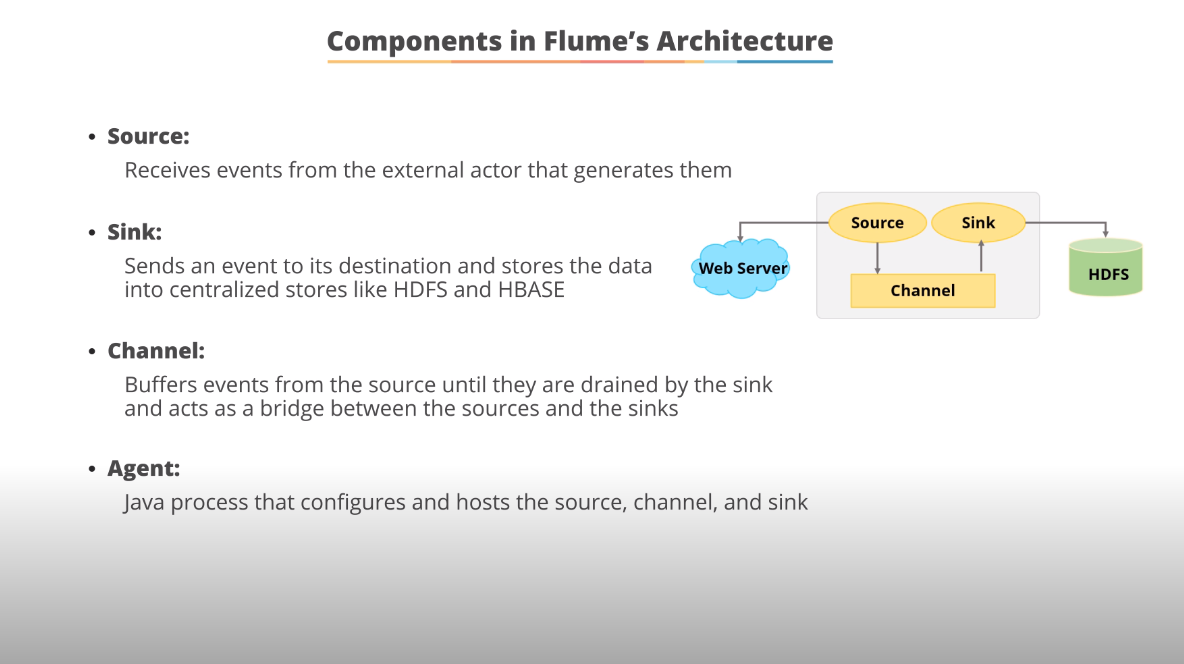
Let's discuss all the components of flume architecture in detail
Flume Event
An event is the basic unit of the data transported inside Flume. It contains a payload of byte array that is to be transported from the source to the destinationaccompanied by optional headers. A typical Flume event would have the following structure.
Flume Agent
An agent is an independent daemon process (JVM) in Flume. It receives the data (events) from clients or other agents and forwards it to its next destination (sink or agent)Source
A source is the component of an Agent which receives data from the data generators and transfers it to one or more channels in the form of Flume events. Apache Flume supports several types of sources and each source receives events from a specified data generator. Example - Avro source, Thrift source, twitter 1% source etc.Channel
A channel is a transient store which receives the events from the source and buffers them till they are consumed by sinks. It acts as a bridge between the sourcesand the sinks. These channels are fully transactional and they can work with any number of sources and sinks. Example - JDBC channel, File system channel, Memory channel, etc.
Sink
A sink stores the data into centralized stores like HBase and HDFS. It consumes the data (events) from the channels and delivers it to the destination. Thedestination of the sink might be another agent or the central stores. Example - HDFS sink
Collector
The data in these agents will be collected by an intermediate node known as Collector. Just like agents, there can be multiple collectors in Flume.
Finally, the data from all these collectors will be aggregated and pushed to a centralized store such as HBase or HDFS. The following diagram explains the data flow in Flume.

Multi-hop Flow
Within Flume, there can be multiple agents and before reaching the final destination, an event may travel through more than one agent. This is known as multi-hop flow.Fan-out Flow
The dataflow from one source to multiple channels is known as fan-out flow. It is of two types- Replicating
- Multiplexing
Comments
Post a Comment