In this section of the blog we will talk about Spark Introduction, its History, why do we need spark and what are the benefits and limitations of Spark.
Well, we know that Spark is used for Data Processing. So the question arises out of it that when we had the Map Reduce tool for Data Processing which was working fine then why do we need any other tool for processing all of a sudden?
What is Spark
It is an open-source, wide range data processing engine. That reveals development API’s, which also qualify data workers to accomplish streaming, machine learning or SQL workloads which demand repeated access to data sets.
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop. MapReduce and it extends the MapReduce model to efficiently use more types of computations.

History of Spark

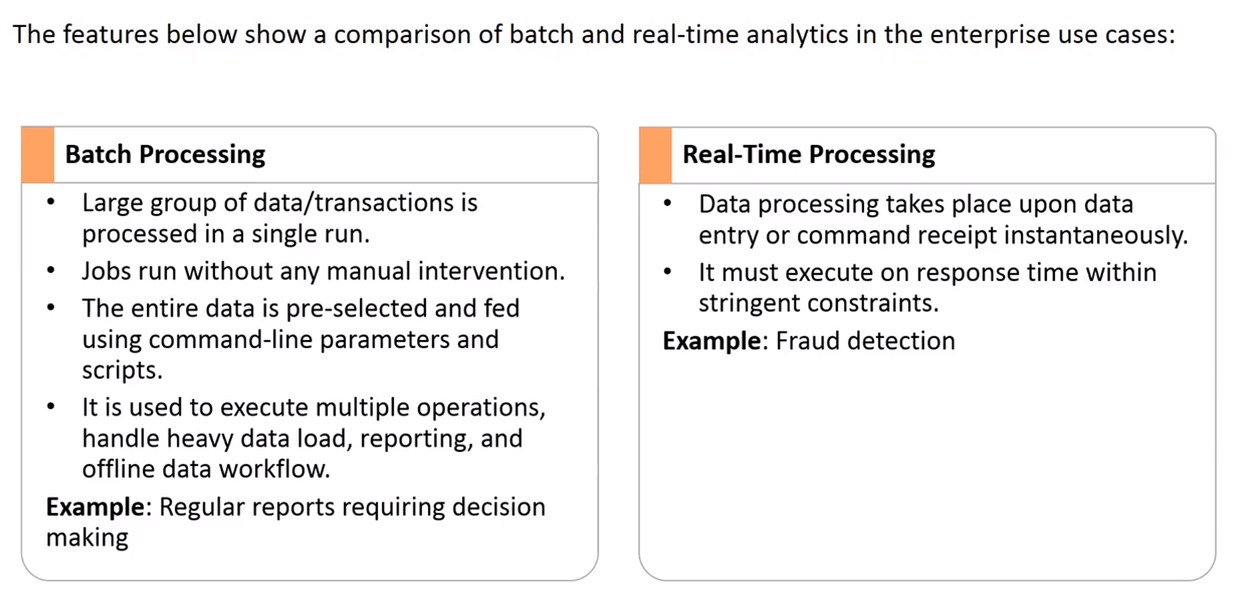
Moreover, Spark Can perform both Batch processing and stream processing. Let's know the difference between the Batch and Real time processing.
Let's discuss what exactly was the limitation of Map reduce due to which we needed Spark and why the companies are moving to Spark over Map Reduce.


Now that we have seen the limitations of Map reduce let's see the advantages of Spark over Map reduce. Shall we?


Different Modes of Spark
Generally people misunderstood that Spark is an alternative or an extension to Hadoop. In reality that's not the case, infact Spark is built on top of Hadoop. Basically Spark use Hadoop for storage purpose only.


Moreover, it is designed in such a way that it integrates with all the Big Data tools.

And also, On comparing Spark with Hadoop, it is 100 times faster than Hadoop In-Memory mode and 10 times faster than Hadoop On-Disk mode.
Let's check the application of In-Memory processing

Architecture of Spark


Components of Spark


We will further discuss the components of Spark in details in the next lesson.
Let's summarize whatever we have learned above. Mentioning bullets points.


Comments
Post a Comment